
The Hidden Queries AI Actually Searches
Fifteen thousand prompts went into ChatGPT. Forty-three thousand two hundred and thirty-three searches came out the other side.
That's not a typo. AirOps ran the numbers across half a million retrieved pages and found that one prompt doesn't trigger one search. It triggers nearly three. 95% of those searches show zero monthly volume in any keyword tool you own.
So here's the question I keep asking myself, what was the keyword research actually for?
I'm not being dramatic about this. I'm being literal.
You've spent years building a content strategy around the query the user types. That's the entire model. One search, one set of ranked pages, one shot at the click.
AI search doesn't work like that.
What's actually happening when AI searches something
Let's use a real example. Someone types "best steakhouse in Portsmouth" into ChatGPT.
You'd expect ChatGPT (or whatever flavour of AI Assistant you like to use) to search that. It doesn't.
What it actually does is decompose that single query into a handful of sub-queries it generates internally, then fires them in parallel before it ever touches the open web. Think of it less like a librarian fetching one book and more like sending five researchers off in different directions at once, each one chasing a different angle of the same question.
ChatGPT generates somewhere between 3 and 8 of these hidden sub-queries per search. Google's AI Mode runs hotter, typically firing 8 to 12. Gemini is the most aggressive of the lot, averaging 10.7 fan-out queries per prompt according to Seer Interactive's research.
This is the process the industry's started calling query fan-out. One user query goes in. A scattering of internally generated sub-queries comes out. Each one gets searched separately. The results get pulled back together into a single synthesised answer.
Lily Ray put it well when Digiday asked her about it: “in the background, the model is extrapolating every next step the user might care about, before it's shown a single result.”
Here's the part that should land. The user never sees this happen. Neither does your keyword tool. The query you're optimising for might not be one of the queries actually being searched.
Your keyword strategy isn't wrong. It's incomplete.
I want to be careful here, because it's easy to hear "fan-out" and think your last twenty years of keyword research just got binned. It didn't, not by a long way.
Traditional SEO answers the query the user typed. That's still real. People still type things into Google, AI Overviews still draw from rankings, none of the principles of that have evaporated, just the CTR 🤬.
What's changed is there's now a second layer sitting underneath it. And that layer doesn't care what your keyword tool says.
People Also Asked questions and fan-out queries get confused constantly, but they're not the same thing. PAA is built from search popularity. This is what people commonly type. Fan-out is built from what the AI thinks / reasons it needs to answer the users prompt. They overlap sometimes. They are not the same animal.
This matters because fan-out queries aren't really predictable from keyword research the way you're used to doing it. They come out of the model's own reasoning process, not out of search demand. Run the same prompt through a keyword tool and a fan-out extractor side by side and you'll get two genuinely different lists.
And the implication for content strategy is the bit that actually stings: AirOps and Kevin Indig's research found pages covering just 26 to 50% of fan-out sub-queries outperformed pages that covered all of them. Not by a little. Meaningfully.
That's the opposite of what twenty years of "build the most comprehensive page" thinking trained you to expect.
One in three of your AI citations is coming from a query layer you can't see and can't measure with the tools you've got open right now. Not "might be". Is.

Your strategy isn't broken. It's missing a layer.
How to find fan-out queries yourself
A few ways, ranked roughly by how much faff is involved.
Chrome DevTools (free, fiddly, breaks occasionally)
You run a prompt in ChatGPT that triggers a web search, copy the URL slug from the address bar, right-click into Inspect, head to the Network tab, refresh, and paste that slug into the filter. Click the matching file, go to the Response tab, search for search_model_queries. That's your fan-out list.
I'll be straight with you: this method has broken before. ChatGPT changes its HTML structure and the field disappears for a while, then it comes back. It's not a permanent fixture, it's a workaround. Treat it that way.
Sam Steiner's Fanout extension (the one I'd actually recommend)
This is the standout. It sits as a side panel next to ChatGPT and shows you every search query the model generated, the sources it cited, the named entities it picked up, even a domain frequency table. The bit I really like: it runs entirely locally. No external requests, no tracking, everything stays in your browser's local storage.
If you're doing this for client work and privacy matters to you, this is the tool to reach for first.
QueryFan.com (if you don't want to touch DevTools at all)
Mark Williams-Cook built this one. It uses the OpenAI and Gemini APIs with real search switched on to show you the actual searches an LLM fires for a given persona and topic. Worth a mention here not only because its my favourite of the bunch but because Mark's doing genuinely useful work in this exact space, well actually in just about every space to do with search. Go and follow what he's building.
Qforia (for scale, but know what you're getting)
Mic King (@VeryWellVersed) and the team at iPullRank built this to model what Google's AI Mode would likely search, based on the routing logic Google's published. The distinction matters: DevTools and the Fanout extension show you what ChatGPT actually searched. Qforia shows you what it would probably search. Both useful. Not the same thing.
Here's the comparison if you're picking which one to start with:
| Method | What it shows | Best for | Limitations |
|---|---|---|---|
| Chrome DevTools | Actual ChatGPT searches | One-off research | Fragile, breaks on ChatGPT updates |
| Fanout extension (Sam Steiner) | Actual searches, sources, entities, stored locally | Agency work with privacy concerns | ChatGPT only |
| QueryFan.com | Actual searches via API with real search enabled | Persona-based research | Requires API access, in beta |
| Qforia | Synthetic modelled sub-queries for Google AI Mode | Bulk analysis at scale | Predictive, not observed |
| DataForSEO API | Fan-out data for ChatGPT, Gemini, Claude, Perplexity | Programmatic, at scale | Paid, £1.20 per 1,000 |
| SE Ranking Extractor | Up to 10 prompts, CSV export | Quick comparisons | Capped prompt volume |
None of these gives you a stable list. Run the same query twice and you'll get different sub-queries back. That's not a bug in any of the tools. That's the actual behaviour of the model, and it's worth sitting with for a second rather than rushing past it.
So you've got the queries. Now what?
This is where extraction turns into actual strategy, and it's the part most fan-out content skips entirely.
Map what you've extracted against the content you already have. Which fan-out clusters does your existing page already answer? Which ones are a flat gap? You'll usually find a mix.
Don't just list them. Cluster the fan-out queries by the intent facet they're probing — local proof and reviews, pricing models, agency process, alternatives, trust signals, or whatever fits the topic. This turns a scattered list of hidden queries into a clear map of which parts of the full user intent your page already owns, and which ones are gaps. It's the same intent clustering you've always done, just applied to the layer your keyword tools can't see.
Kevin Indig's research found something specific here that I think is the single most actionable line in this whole topic: subheadings that directly match fan-out query language are the ones that get selected for citation. Not subheadings that match your target keyword. Subheadings that match the language of the actual sub-query.
That means going back through your H2s and H3s and rewriting them to speak the model's language, not your SEO brief's language.
The "ski ramp" pattern is the other one worth building around. 44.2% of all ChatGPT citations come from the first 30% of a page. If your best answer is buried at paragraph nine, you've already lost most of your shot at being the one that gets cited. Front-load the answer. Save the nuance and caveats for after.
There's a third principle worth knowing, which comes from DEJAN's work on semantic compression: every passage on your page needs to carry its own context, because it might get lifted out and read in total isolation by a retrieval system. If a paragraph starts with "it does this well," and "it" only makes sense if you'd read the three paragraphs above, that passage has already failed before it's even been considered. Name the entity. Every time. Even when it feels repetitive to a human reader.
Here's the reframe for how you actually structure content going forward.
The old model: one pillar page, covering everything, as comprehensively as you can manage.
The new model: map your fan-out clusters first, then build a cluster architecture where each page is the single best answer to one specific sub-query, rather than an adequate answer to five.
This isn't an argument for thin content. It's an argument for modular content. One precise answer beats five adequate ones, and that's not me being provocative, that's what the data actually shows.
Where this gets shaky, and I want to be straight about that
If a piece on this topic doesn't have a limitations section, I don't trust it. So here's mine.
Fan-out queries are not stable. Run the same prompt through the same model multiple times and you'll get different sub-queries back. Seer Interactive ran one keyword through Gemini 124 times and found 25 distinct topic clusters across those runs. The model isn't deterministic. It's making slightly different decisions every time you ask.
The extraction methods are genuinely fragile. ChatGPT's HTML structure has changed before and the search_model_queries field has disappeared for stretches at a time. Anything built on top of DevTools extraction is built on a foundation that might shift under you with the next product update.
Synthetic modelling gives you a probability, not a fact. Qforia tells you what's likely. It's not the same as watching what actually happened.
And the honest one: we don't yet have clean proof that optimising specifically for fan-out queries causes more AI citations. What we have is correlation. Pages that happen to cover fan-out sub-queries well get cited more. Whether deliberately optimising for them moves the needle the same way, over time, at scale, is something nobody's proven yet. Including me. Also, I should be clear on this, I am in no way advocating trying to place your whole strategy on the hope of citations.
If someone tells you this is solved and proven, they're selling you something which starts with snake and ends with oil.
Why I built a tool instead of just doing this by hand again
I got tired of doing the gap analysis step manually for client work and built a free tool to automate it.
That's genuinely the whole origin story. Doing the mapping above by hand for one client is fine. Doing it for ten clients, every month, by hand, is not a real workflow. It's a way to burn a day and develop a severe dislike for your work.
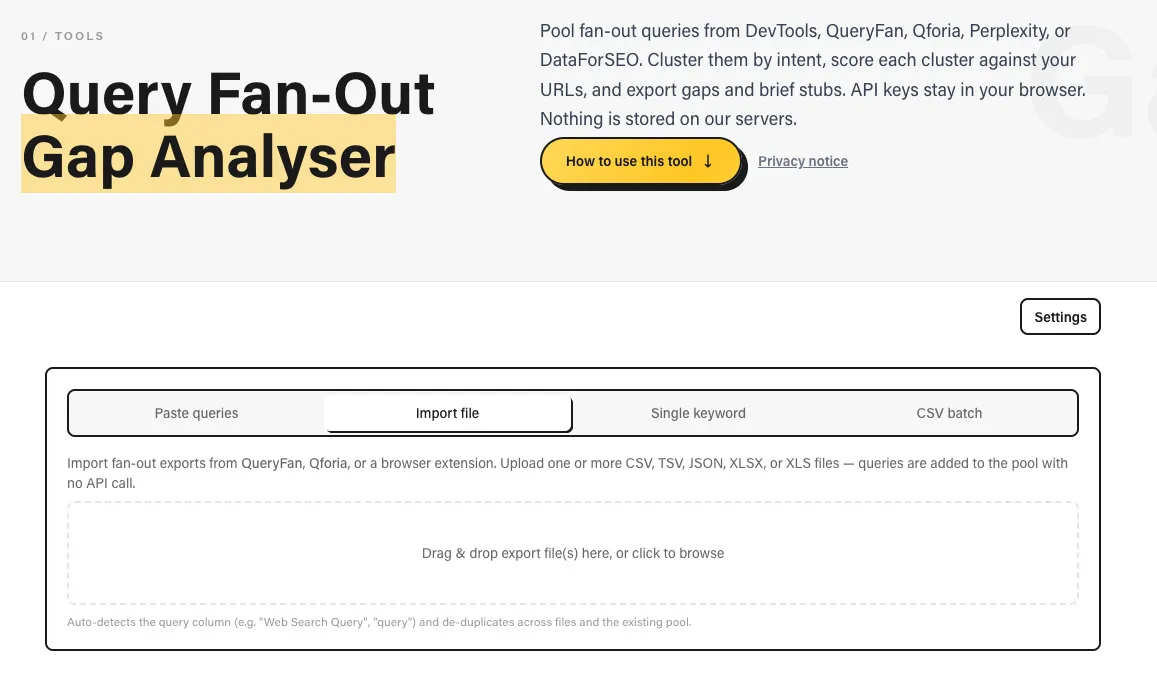
What it actually does: it pools fan-out queries from whichever extraction method you used (personally I try and use them all), paste them in from DevTools or the Fanout extension, import a Qforia export, or pull them programmatically via Perplexity or DataForSEO, clusters them into semantic intent buckets, then lets you check each bucket against a URL you nominate. It tells you whether that page covers the cluster, partially covers it, or misses it entirely, and whether the right move is to integrate that gap into an existing page or build something new and focused.
What it doesn't do, because I don't want to oversell this: it doesn't predict citations. It doesn't replace proper keyword volume research. It doesn't crawl your whole site automatically and hand you a finished content calendar. You still nominate the URL. You still make the call.
If you run it and find an edge case that breaks, or a gap in the logic, I genuinely want to hear about it. This is early, and the best version of this tool gets built in public, not in isolation.
How Does Incorporating Fan Out Queries Affect My Content Strategy?
I'll say the same thing I'd say if you asked me about this over a pint rather than reading it in an article: this isn't a reason to panic, and it's not a reason to ignore it either.
A third of your AI citation surface is sitting in a layer your current tools can't see. That's worth twenty minutes of your week to go and actually look at, even before you touch the tool. Run one of your own queries through the DevTools method. See what comes back. I'd put money on at least one of those sub-queries surprising you.
That's really all this is. Not a new tactic. A different way of looking at the same problem you've always been working on.