
CTR Is Dead for AI Search. Here's the Metric That Replaces It, and How to Actually Improve It
The Problem With Everything You’re Currently Measuring
Your CTR report is measuring a behaviour that’s disappearing.
Organic CTR on queries with AI Overviews fell from 1.76% to 0.61% over 15 months. That’s a 61% collapse, tracked across 25 million impressions by Seer Interactive. Ahrefs ran their own numbers in February 2026 and found position-one CTR drops 58% the moment an AI Overview shows up on a SERP. 64.82% of Google searches now end without a click at all, up from roughly 50% in 2019.
Sadly, that’s a reality and not a .
The metric SEOs have reported on since 1998 is no longer the primary decision point. Clicks were never actually the goal. They were a proxy for it. CTR worked as a measurement because search results used to be a list of ten blue links and a human chose one. That mechanism is breaking down, query by query, and no amount of cleverer meta descriptions fixes it.
Here’s the stat that matters more than any of the decline numbers above. Brands cited inside AI Overviews earn roughly 120% more organic clicks per impression than uncited brands on the exact same queries.
Read that twice. Citation beats ranking. Not "correlates with ranking." Beats it, on the same SERP, for the same query, for the same searcher.
So the real question stops being "how do I get my CTR back." You don’t, sorry but that’s facts and chasing it for another quarter is a waste of a budget line. The real question is: what determines whether you get cited? That’s what the rest of this article is about, and it’s a more useful question than the one most agencies are still asking their clients to live and die by.
What Actually Happens When Google's AI Mode Generates an Answer
Think of the AI Mode pipeline like a recruitment process, not a popularity contest. Most SEOs are still optimising for the CV screening stage and wondering why they’re not getting the job.
Here’s the full pipeline, in order, and most of the SEO industry has only properly clocked stage one.
-
Information Retrieval. Google’s standard index runs first. Same ranking signals apply here as they always have: PageRank, E-E-A-T, domain authority. If you’re not indexed and ranking, you don’t get shortlisted for anything downstream. Traditional SEO is still the price of admission, not a relic from a previous era.
-
Fan-Out. Before Gemini ever searches anything, it generates a batch of sub-queries internally. I covered this layer properly in the fan-out article, this is where the model decides what it actually needs to know before it goes looking.
-
Grounding and Shortlisting. For each fan-out query, Google shortlists somewhere between 5 and 20 sources. It then extracts snippets from those pages. Not the full page. A snippet.
-
Selection. The model compares the shortlisted snippets and decides which passage, or passages, to use when building the answer. This is the SRO layer. The model isn’t reading your page. It’s judging an extracted block entirely on its own merits, with zero context from the rest of your site.
-
Synthesis. Gemini writes the final answer using whichever passages won the selection round, with citations attached for the ones it used.
Most SEOs are optimising for stage one. SRO is about winning stage four. You can rank number one for a query and still lose the selection contest to a competitor sitting at position six, because the model isn’t reading position. It’s reading the passage in front of it.
Google’s own AI Optimization Guide confirms this pipeline runs on retrieval-augmented generation. This isn’t a theory I’m proposing to sound clever. It’s documented, by Google, in their own developer docs.
The Grounding Budget: Why Your Page Length Strategy Might Be Wrong
Dan Petrovic at Dejan AI ran the numbers. 7,060 queries. 2,275 tokenised pages. The output is some of the most useful empirical data in AI SEO right now, and barely anyone outside Dejan’s own client base has actually acted on it.
The headline finding: every query has a fixed grounding budget of roughly 2,000 words, shared across every source Google decides to ground from for that query. Your rank position determines your slice of that fixed pie.
| Rank Position | Share of Budget | Word Allocation |
|---|---|---|
| #1 | 28% | ~531 words |
| #5 | 13% | ~266 words |
Most pages don’t get anywhere near that much. 77% of pages get somewhere between 200 and 600 words selected. The typical page across the dataset gets about 377 words pulled into the answer.
Here’s where it gets uncomfortable if you’re running a "comprehensive 4,000-word guide" content strategy. Grounding plateaus at around 540 words. Push a page past 2,000 words and you see diminishing returns, not because the extra content is bad, but because it dilutes your coverage percentage without increasing what actually gets selected from it.
The numbers back this up starkly. A concise 800-word page can pull 50%+ coverage of its own content into the grounding budget. A 4,000-word page on the same topic, ranking higher, might pull 13%.
Density beats length. Full stop. The "ultimate guide" content strategy was built for a different era, one where length signalled authority to a crawler that read the whole page front to back. A tight 800-word page ranking second can outperform a sprawling 4,000-word guide ranking first, purely on grounding coverage. That’s a genuinely strange sentence to write as someone who’s spent two decades telling clients that longer, more comprehensive content wins.
I’ll give the counter-argument its due, because it’s a real one and not a strawman. Mike King at iPullRank argues that a long page, if it’s structured with an answer-first approach in every single section, multiplies its retrieval surface rather than diluting it. Each section becomes its own extractable unit, competing independently. That’s a genuinely open question right now, not a settled one, and I’d rather tell you that honestly than pretend Dejan’s data closes the debate when it doesn’t.
What Is Selection Rate Optimization (SRO)?
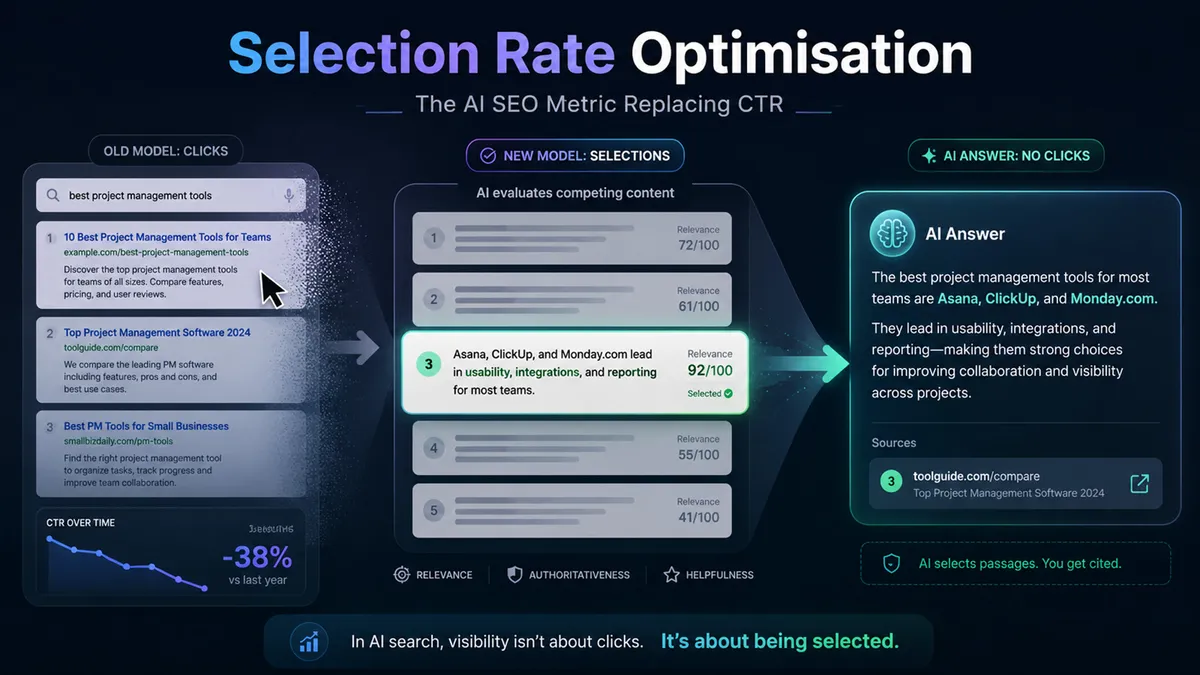
Selection Rate Optimization is an AI SEO discipline that leads to the preferential treatment of target brands, products, and services in AI search. When an AI model is handed multiple grounding candidates, it reviews snippets from each source and decides which one to select. How often your content wins that decision, against your competitors, is your Selection Rate. SR is the AI-era equivalent of CTR.
Here’s the analogy that makes it click. CTR measured what happened when a human saw your title in a results list and decided whether to click it. SR measures what happens when an AI model sees an excerpt from your page sitting next to excerpts from your competitors, and decides which one to quote in its answer. Same decision moment. Completely different decision-maker, working off completely different criteria.
Scott Stouffer from Market Brew put it well on LinkedIn:
"The move from CTR to selection probability reflects how grounding actually works. Models do not read pages; they evaluate small, self-contained snippets. If a chunk cannot stand on its own or lacks clarity, it will usually not be selected."
I want to be clear about credit here, because this matters. Dan Petrovic, Director of Dejan AI and Adjunct Lecturer at Griffith University, coined and formally published this framework. He’s the primary voice in this space, mainly because he seems to live in the trenches testing. What I’m doing in this article is translating his framework for an agency practitioner audience, and building a simplified, accessible version of his pipeline that doesn’t require a research team to run. I’m not claiming to have invented any part of the underlying concept, and you shouldn’t read this article that way.
Snippet Anatomy: What Makes a Passage Irresistible to a Selection Model
This is the practical section. What does a passage that actually wins selection look like, structurally? Five principles, all grounded in Dejan’s published research.
Principle 1: Semantic Compression
This is the single most important structural rule for AI-selected content. Every chunk you write has to carry its own context, because it might get extracted and read in total isolation by a retrieval system that has never seen the three paragraphs sitting above it.
If a passage opens with "it performs particularly well here" and "it" only makes sense if you’ve already read everything that came before, that passage has already failed before a model even gets to judge it on substance. Name the entity. Every single time, not just on first mention.
❌ "It performs particularly well in comparison to alternatives on this metric."
✅ "ahrefs performs particularly well on keyword volume accuracy compared to SEMrush and Moz on this specific metric."
The second version survives being extracted and read cold by a model with zero surrounding context. The first one doesn’t survive at all. It just becomes noise the chunking process throws away.
Principle 2: Answer-First Architecture
AI retrieval systems extract the opening of every section, more or less regardless of what comes after it. Sentences that closely resemble the search query get strongly favoured during scoring. Abstract throat-clearing, scene-setting, and the kind of warm-up paragraph most blog posts open with, all get skipped entirely.
The practical rule: the first 40 to 60 words of every section need to directly answer the question the heading implies, written as a complete, self-contained statement. Not a teaser for what’s coming. The actual answer, immediately.
Principle 3: Entity Salience
The retrieval pipeline scores passages on how closely they match the fan-out query that triggered the search. Passages that explicitly name the actual entities, topics, and concepts contained in the query score meaningfully higher than passages that only gesture at them obliquely or rely on synonyms. Don’t make the model do the work of inferring what you’re actually talking about.
Principle 4: Factual Density Over Narrative Fluency
Data-backed snippets show roughly 40% higher citation rates than purely conceptual ones. The model is prioritising verifiable information, statistics, dates, specific figures, concrete examples, over general claims that sound polished but say nothing measurable. "Our tool is fast and accurate" loses every time to "our tool processes 10,000 keywords in under 4 seconds with a reported 94% accuracy rate."
Principle 5: Optimal Passage Length
Target 60 to 120 words per passage, roughly 100 to 300 tokens. That’s the sweet spot for LLM extraction. Long paragraphs that blend two or three ideas together are effectively invisible to retrieval models, not because they’re badly written, but because the chunking process fragments their meaning right across whatever boundary it happens to draw through them.
One technical note worth knowing, even if you skip the maths entirely. Dejan’s pipeline uses a cross-encoder, the same type of model Bing trained on billions of real search queries, to reconstruct the grounding snippets Google generates. That matters because it means this simulation is calibrated against actual large-scale search behaviour, not a generic language model guessing at what looks relevant.
The SRO Pipeline: How to Run a Simplified Version Yourself
Dejan’s process is the reference framework here, built for a research and enterprise context. My contribution is translating it into something an agency practitioner can actually run with free or low-cost tools, on a real client account, without needing a data science team on standby.
-
Define your key entities. What brand, product, or service are you actually optimising for? Be specific, not "SEO software" but "the specific product page for [your tool]."
-
Generate fan-out queries. Use Chrome DevTools, the Fanout extension, or QueryFan.com to surface the sub-queries an AI would actually fire for your topic. I built the Query Fan-Out Gap Analyser for exactly this step, covered in full in the fan-out article.
-
Run grounding candidate discovery. Use snippets.Dejan.ai to see which URLs Google is actually grounding from for each fan-out query, and the exact sentences it’s pulling from each one.
-
Define your real competitors. The other pages sitting in that grounding shortlist are who you’re actually competing against for selection. Not your usual SERP rivals in general. These specific pages, for this specific query, right now.
-
Generate your grounding snippets. Use snippets.Dejan.ai again to see the exact passage extracted from your page, and the exact passage extracted from each competitor’s page.
-
Measure your Selection Rate. Run a judge-model pass. Present your snippet alongside the competitor snippets to a capable LLM, Claude, GPT-4o, Gemini, it doesn’t massively matter which, with a prompt along these lines: "Here are five passages about [topic]. Which one would you select to answer this query: [query]? Score each from 1 to 10 and explain your reasoning." This is the accessible, manual version of Dejan’s cross-encoder pipeline.
-
Rewrite and re-test. Apply semantic compression, answer-first structure, and entity salience fixes to your passage. Run the judge pass again. Repeat until your snippet consistently wins against the field.
-
Implement and observe. Publish the changes. Track grounding shifts in Search Console, specifically AI source impressions, and via snippets.Dejan.ai, over the following few weeks.
A note on the tool. I built an SRO Snippet Tester to automate steps 4 through 7 above, because this whole process used to be manual, a bit clunky, and held together with browser tabs. There was no accessible agency-level version of this pipeline anywhere, and that was a gap worth closing.
How the SRO Snippet Tester Actually Works
It runs the selection contest in three layers, and it shows its working at every step rather than handing you a single black-box number.
Layer 1: deterministic structural scoring. Before any AI is involved, every passage is scored on seven structural dimensions in plain, transparent code: answer-first directness, entity salience, semantic self-containment, factual density, passage length fit, query-match strength, and clarity. That’s the five snippet-anatomy principles from earlier, plus two extra checks, one for how closely your language mirrors the query, one for whether a single idea reads cleanly. This layer runs in your browser too, which is why you get live structural hints as you type, and a free structural preview before you’ve added any API key at all. There’s a worked example loaded in, so you can see the whole thing run end to end before committing a single keystroke of your own.
Layer 2: the judge model. This is the part that stands in for Google’s selection step. Your snippet and the competitor snippets are handed to Gemini, which scores and ranks them on the same seven factors, names a winner, and explains in plain language why each passage won or lost, with specific strengths and weaknesses, plus its own confidence level in the verdict. It runs on Gemini Flash by default and automatically escalates to Pro when the contest is close or the cheaper model isn’t confident enough. The judge prompt is deliberately strict: no credit for label or position, and harsher penalties for vague, context-dependent passages than a general-purpose LLM would hand out left to its own devices.
The blend. The final score for each passage is 75% judge and 25% deterministic, turned into an estimated Selection Rate, the passage’s share of the contest expressed as a percentage. The judge carries most of the weight because it’s the closest proxy we have to the real decision-maker. The structural layer keeps it honest, and stops a fluently written but structurally weak passage from winning on charm alone.
Pulling real passages, not guesses. You can paste passages directly, or hand the tool a URL. Give it a URL plus your query and a Gemini key, and it fetches and cleans the page, then asks Gemini to pull the up-to-five verbatim excerpts most likely to be selected for that query, validating every quote against the source text so it can’t paraphrase or invent a passage. With no key, it falls back to a keyword-overlap heuristic that chunks the page into 60–120 word candidates, and it tells you, on screen, exactly which method it used and why it fell back. That transparency matters, because a keyword-guessed competitor snippet is not necessarily the one Google actually cites.
It tells you when not to trust it. This is the part I care about most. The tool actively warns you when the inputs could mislead: when a competitor passage was keyword-guessed rather than AI-selected, when your passage was extracted more favourably than a competitor’s, when the margin of victory is thin enough that a small edit could flip it, when the judge isn’t confident, and a standing reminder that it only simulates passage-level selectability. It cannot see real citation history, domain authority, or whether Google has ever actually cited your page. If a competitor keeps winning in live AI Overviews while the tool says you win, the passage you pasted for them is probably not the one being cited, and the tool says exactly that rather than letting you walk away with false confidence.
The rewrite. Once you’ve tested, it generates an SRO-optimised rewrite of your passage, applying semantic compression, answer-first structure, and entity salience, with a hard rule that it never invents statistics it wasn’t given. It returns structured notes on what changed and why, plus a plain-English explanation you can paste straight into a content brief, and you can re-test the rewrite on the spot. Results export to Markdown or JSON when you want to drop them into a deck or a ticket.
On privacy and cost. It’s free, runs in your browser, and uses your own Gemini API key on a Bring Your Own Key basis. The key is stored only in your browser and passed straight to Gemini through the tool’s own API routes, never stored on a server, and there’s no database, so nothing you test is retained anywhere. You’re only ever paying Google for your own API usage, and Flash is cheap.
👉 Try it now: the SRO Snippet Tester. Paste your passage and the competing passages for a grounded query, or feed it a URL, and it scores every snippet, ranks them, estimates a selection rate, and generates an SRO-optimised rewrite you can re-test on the spot. Steps 3 and 8 of the pipeline above still lean on snippets.Dejan.ai and Search Console, which is exactly where they belong.
The Agency Version: What to Report to Clients
This is the bit nobody else seems to be writing about, because most of the AI SEO content out there is still talking to other SEOs, not to the people actually paying the retainer.
SRO isn’t just a content tactic. It’s a new reporting framework, and the old one genuinely doesn’t translate onto it.
| Traditional SEO Reporting | SRO Reporting |
|---|---|
| Keyword rankings (position 1-10) | Grounding candidate inclusion rate |
| Organic CTR | Selection Rate vs. competitor passages |
| Page traffic | Grounding snippet coverage % |
| Number of featured snippets | Passage-level E-E-A-T quality score |
Here’s roughly what I’d actually say to a client in that meeting: "We’re no longer just optimising to rank. We’re optimising to be the passage the AI picks over your competitors. The question isn’t whether you appear in search results anymore. It’s whether the AI reads your content or theirs when it’s actually building its answer."
The honest caveat. This reporting model is new, and there’s no off-the-shelf dashboard for it yet, whatever any vendor tells you. What exists right now is Search Console for AI Mode impressions, snippets.Dejan.ai for grounding candidate visibility, and manual judge-model testing for selection simulation. The tools will catch up eventually, they always do. The methodology is right, today, even without a dashboard to make it look pretty in a deck.
What the AI Visibility Score Vendors Are Missing
Most AI visibility tools measure how often a brand appears in response to a static set of monitored prompts, run daily, tracked over time, charted with a line going up and to the right. Dan Petrovic has been blunt about this: daily static prompt tracking is largely a waste of time, and he’s right.
Here’s why. For a huge proportion of queries, the AI is answering from training data, in-model, not from the live web, grounded. If a query gets answered in-model, no amount of content optimisation on your end changes the answer the model gives. The only thing that moves it is influencing training data itself, which is slow, indirect, and not something you control on a monthly content calendar.
If the query is grounded, on the other hand, standard SEO and SRO directly influence what gets cited.
The distinction matters more than the visibility score itself. Tracking your AI visibility for a prompt the model is answering purely from memory is measuring noise dressed up as insight. You can watch that number for six months and it will tell you nothing useful about whether your content strategy is actually working.
SRO operates specifically on grounded queries, the ones where the AI is actively searching, shortlisting, and selecting in real time. It’s a metric built for the part of the system where optimisation can actually change the outcome, rather than the part where you’re just watching a number move for reasons entirely outside your control. I’ll get into the in-model versus grounded distinction properly in the next post in this series, but it’s worth flagging here, because it’s the reason a lot of current AI visibility tracking is quietly aiming at the wrong target.
What This Means for Content Production Workflows
If you’re optimising for SR rather than just rankings, your content workflow needs to change at every stage, not just at the point where someone sits down to write.
Pre-publish. Run a fan-out extraction before you write a single word. Map the actual sub-queries the AI will fire for your topic. This tells you exactly which passages you need to win, before you’ve wasted a day writing ones that were never going to matter.
Writing. Apply semantic compression from the first sentence. Write every passage as if it might be read in total isolation, because there’s a real chance it will be. Name entities explicitly. Front-load the direct answer. Keep passages between 60 and 120 words, and resist the urge to pad them out.
Pre-publish testing. Run the simplified SRO judge-model test before you hit publish, not after. Put your key passages up against competitor passages for the 3 to 5 most important fan-out queries. Are you winning? If not, rewrite it now, while it costs you nothing, instead of finding out in three months when the traffic doesn’t show up.
Post-publish measurement. Use snippets.Dejan.ai to check grounding candidate inclusion. Watch Search Console for AI Mode impressions. Retest in 4 to 6 weeks once Google’s had time to properly crawl and re-evaluate.
Iteration. SRO is not a set-and-forget optimisation, and treating it that way is the most common mistake I expect agencies to make over the next year. The selection model shifts as your competitors update their own content. Treat it exactly like rank tracking. Check it regularly. Update when you’re losing, not once a quarter when someone finally pulls a report.
The structural standards worth building into every content brief from this point forward:
-
Question-based H2/H3 headings that directly match query language, not clever wordplay
-
A direct answer in the first 40 to 60 words of every section, every time
-
60 to 120 word passage length as a hard target, not a suggestion
-
The entity named explicitly in every passage, no pronouns doing load-bearing work
-
Data and statistics included specifically to push up factual density
-
One idea per passage, never multiple topics blended into one paragraph because it reads more "naturally"
Limitations and What We Don’t Know Yet
Every piece I publish gets an honest limitations section. This one needs it more than most, because the whole field is moving faster than the measurement tooling can keep up with, and anyone telling you otherwise is selling something.
-
There is no direct, real-time Selection Rate metric. We can simulate it. We cannot observe it natively in any analytics dashboard right now, full stop. What’s described in this article is a proxy, not ground truth, and it’s important to hold that distinction in your head while you’re running it.
-
The judge-model test is an approximation. A capable LLM scoring your passage against competitors is a genuinely useful simulation, but it isn’t the same model, with the same training data and the same weights, as Google’s actual Gemini-based selection system. Treat the score as directional, not definitive.
-
The grounding budget data comes from one agency’s dataset. Dejan, roughly 7,060 queries. Dan Petrovic has been transparent about that scope himself. It hasn’t been independently replicated at scale yet by anyone else. Treat it as a strong working hypothesis, not proven law, until someone else runs the numbers too.
-
Selection rates vary by query type, topic, and intent. What wins for a product comparison query won’t necessarily win for a factual definition query sitting one click away. Run this pipeline per query cluster, not as a single blanket strategy applied across your whole site.
-
The tools themselves are early. snippets.Dejan.ai shows you what Google actually selected, which is real signal. My SRO Snippet Tester gives you a head-to-head selection score and a rewrite, but it’s a simulation of the contest, not a window into Google’s live decision. Use the two together: Dejan’s tool to see what’s really being cited, mine to test changes before you publish them. Dedicated, fully observable SRO tooling will mature eventually. It hasn’t yet.
What To Do Right Now (If You Don’t Want to Wait for the Tool)
Three things you can do today, with tools that already exist and cost you nothing.
-
Run the grounding snippet check. Go to snippets.Dejan.ai, enter your most important query, and see exactly which sentences Google is pulling from your page right now. If the extracted snippet doesn’t directly answer the query, you’ve just written your own optimisation brief, for free, in under two minutes.
-
Run the judge-model test manually. Take your top three grounding competitors’ extracted snippets from the tool above, plus your own, and paste all four into Claude or ChatGPT with: "Here are four passages about [topic]. Which one best answers this query: [query]? Score each from 1 to 10." Do this across five of your most important queries. The pattern in where you’re losing will become obvious fast, usually within the first three.
-
Apply semantic compression to your top five pages. Pick the pages you most want cited. For each major section, check three things: does it name the entity explicitly, does it answer the implied question in the first two sentences, and is it under 120 words. These three fixes alone move the needle more than most full content rewrites I’ve seen agencies commission this year.
That’s the framework. CTR like we have known it isn’t coming back, and reporting on its decline every month isn’t a strategy, it’s just a slower way of admitting the problem. Selection Rate is measurable, simulatable, and right now, mostly unoptimised by the industry. That’s an opportunity sitting in plain sight, not just another problem to add to the pile.
I’ll cover the in-model versus grounded query distinction properly in another post, because it changes which queries are even worth running this entire pipeline against. Until then, run the three steps above against your top five pages and see exactly where you actually stand.