
I split 15 long-form pages into thirds, wrote 120 queries where the answer lived in a specific passage, and ran the whole thing across ChatGPT, Gemini, Claude and Perplexity. 480 calls in total. One question behind all of it: when an AI cites a page, which bit of it actually gets used?
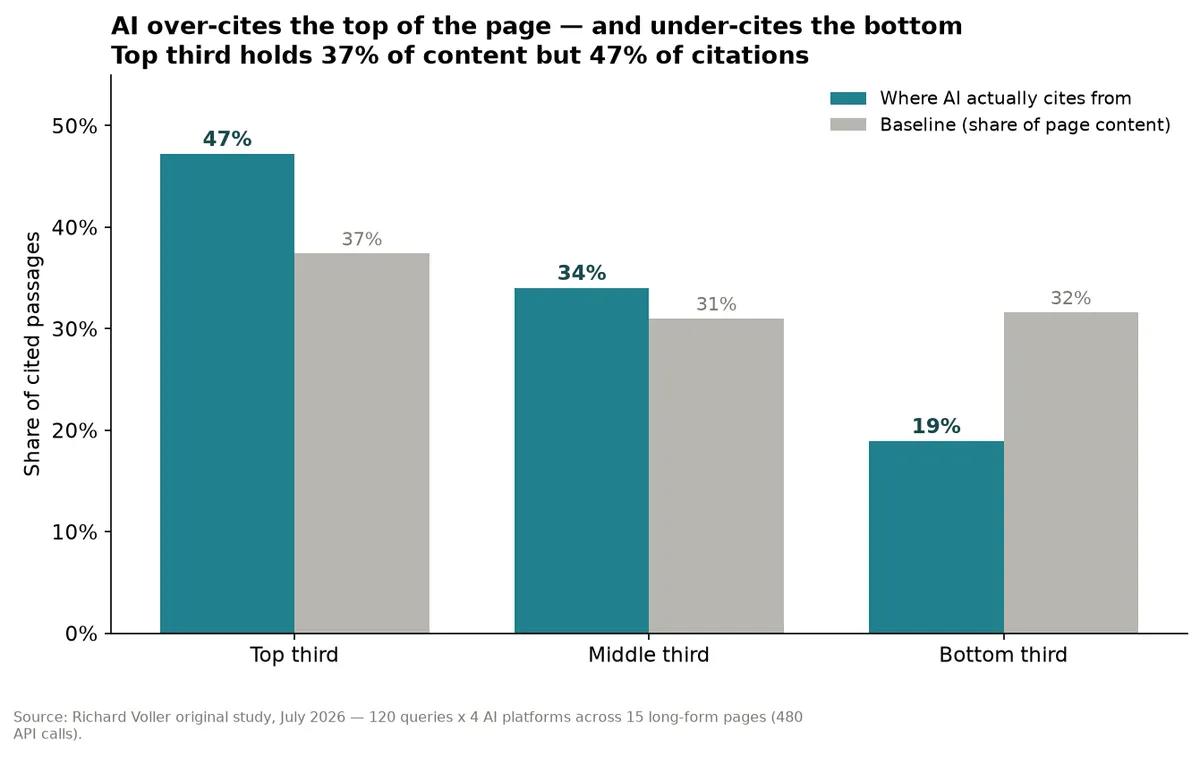
AI assistants over-cite the top of a page and under-cite the bottom of it. Across four platforms, the top third of every page I tested pulled in 47% of citations while holding only 37% of the words. The bottom third held 32% of the content and got just 19% of the citations back. Position decides a lot of it, but format and source authority decide almost as much.
TL;DR
- Top third: 47% of citations, 37% of content. Under-performing bands don't get an even split, they get punished.
- Bullet lists over-index roughly 3x. Small structural edit, outsized effect.
- Third-party pages got cited 3x more than my own. Authority beats "it's my page."
- "Lost in the middle" is real, but it's a lean, not a cliff. Mid-page answers still landed 45% of the time.
- Platforms disagree with each other. Gemini and Claude hug the top, Perplexity leans to the middle, and ChatGPT spreads citations the most evenly of the four.
Why "where AI cites from" matters more than "does AI cite me"
Getting retrieved isn't the win. Getting cited is.
AirOps analysed 548,534 pages ChatGPT retrieved across 15,000 prompts and found it only cited 15% of them, reported by Search Engine Land. The other 85% got read, scored, and binned without a single user ever seeing them.
So the question was never really "was I crawled." It's "which passage got used." Different question, and it's the one this whole piece is actually about.
If you want the layer above this one, whether a query even goes out to the live web at all versus getting answered from the model's memory, I covered that split properly in grounding vs in-model knowledge. This piece assumes you're already in grounded territory. It's about what happens once the model is actually reading your page.
How I tested it
I wanted first-party, passage-level data. Plenty of people publish citation-rate studies. Almost nobody shows you the exact sentence that got pulled, across four platforms, from a page you can go and inspect yourself.
- 15 long-form pages. 5 of mine, 10 third-party industry pages.
- Each page split into thirds (top, middle, bottom) and tagged by format (prose vs list).
- 120 queries, engineered so the answer lived in a known passage.
- Run live across Perplexity, ChatGPT, Gemini and Claude. 480 API calls in total.
- Every answer matched back to the exact source passage it came from.
Finding 1: AI over-cites the top, under-cites the bottom
The top third of a page pulled 47% of citations while holding only 37% of the content. The bottom third lost about 13 points against its fair share.
Picture someone skimming a report on the train. They read the opening properly, skip through the middle, and only catch the ending if the journey's long enough. That's roughly how a model reads your page too, except it never goes back for a second look, and it makes its citation decision off whatever caught its attention the first time through.
My numbers: 47% top, 34% middle, 19% bottom, against a 37/31/32 content baseline. If citations tracked content evenly, each band would land close to its own share. None of them do, and the gap runs the same direction every time.
This isn't a quirk of my 15 pages. It's the same shape the biggest studies in this space keep finding.
Kevin Indig analysed 1.2 million ChatGPT responses and 18,012 verified citations and found 44.2% come from the first 30% of a page, a pattern he calls the "ski ramp" (Search Engine Land).
On Google AI Overviews specifically, Tarek Reslan at CXL ran a 100-citation study and found 55% came from the top 30% (CXL). Different engine to ChatGPT, so don't merge that number with Indig's. But the direction is identical.
Why does the same bias show up across completely different systems? Stanford's "Lost in the Middle" research found language models retrieve information best from the very start and very end of a context window, and worst from the middle of it (arXiv). MIT's research on causal masking found the actual mechanism behind it: the attention structure inside a transformer inherently biases the model toward whatever it read first, and that bias compounds the deeper into the model you go (MIT News).
Put plainly, this isn't a bug anyone's about to patch. It's built into how the architecture reads.
The practical read-across is the one I wrote up properly in Selection Rate Optimisation. Front-loading isn't a nice-to-have style preference. It's a selection lever, and on this dataset it's the biggest one I found.
Finding 2: The platforms don't agree on where they pull from
Gemini and Claude hug the top of the page. Perplexity is the outlier that leans toward the middle. ChatGPT spreads its citations the most evenly of the four.
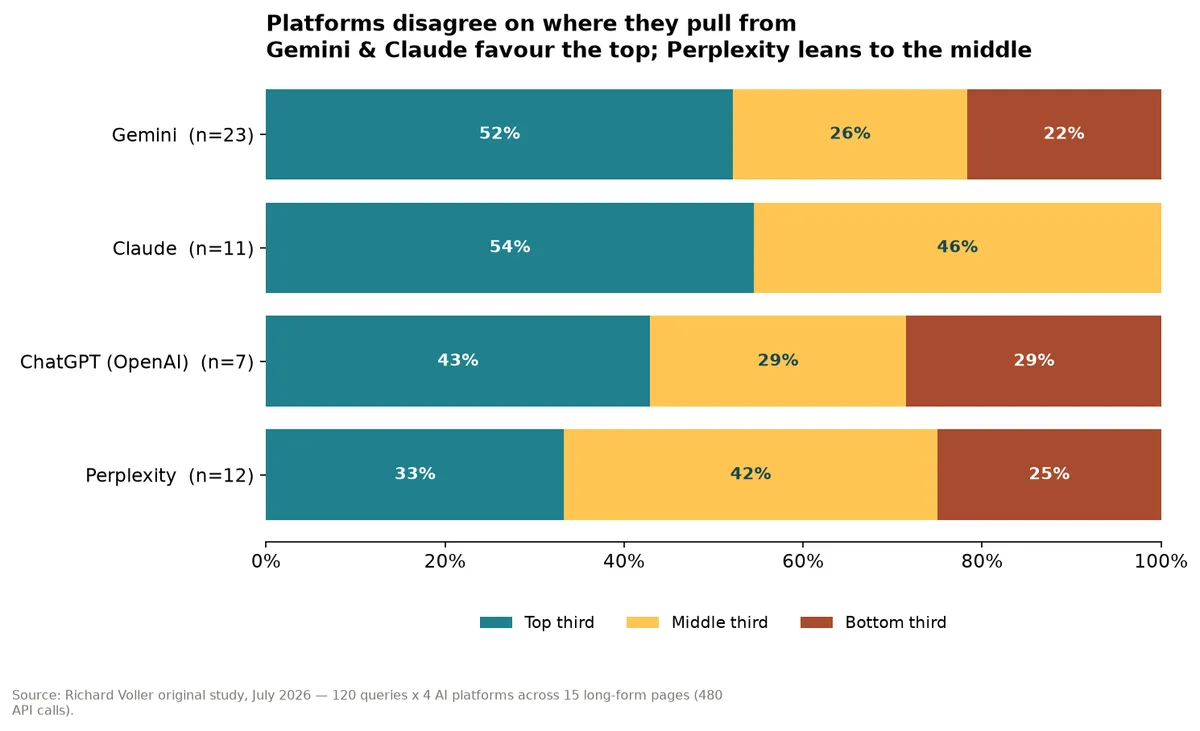
| Platform | Citations from the top third |
|---|---|
| Claude | 55% |
| Gemini | 52% |
| ChatGPT | 43% |
| Perplexity | 33% (42% from the middle) |
If Perplexity matters to your traffic mix, mid-page content has a fighting chance it simply doesn't get on Gemini.
This lines up with what AirOps and Kevin Indig have both reported on retrieval rank: position 1 in the retrieval pool gets cited roughly 3.5 to 4 times more often than position 10 (Search Engine Land). Rank in the page and rank in the retrieval pool pull in the same direction, and they stack.
I've written before about why platforms fan a single query out into dozens of sub-queries in the first place, which is a big part of why this split between them exists at all. Worth reading if you haven't: reverse-engineering fan-out queries.
Finding 3: Gemini cited the source page 3x more than ChatGPT
Gemini cited the exact page holding the answer 19.2% of the time. ChatGPT managed 5.8%. That's over 3x.
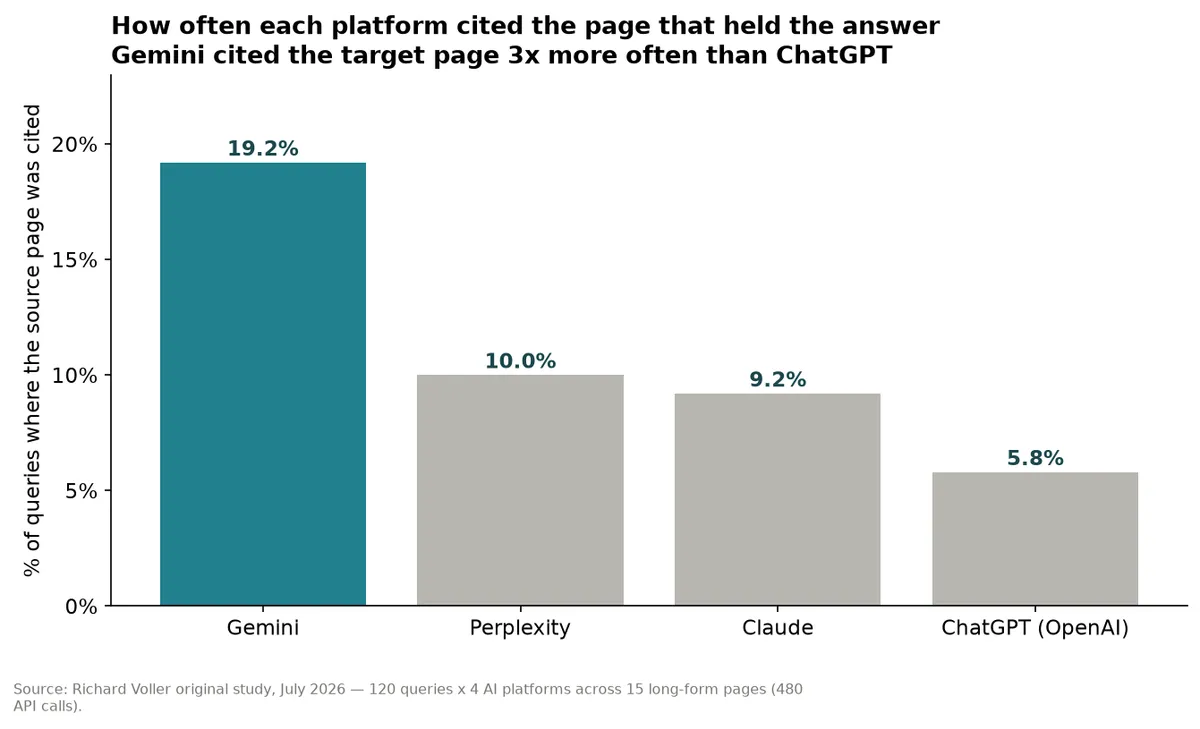
| Platform | Cited the target page |
|---|---|
| Gemini | 19.2% |
| Perplexity | 10% |
| Claude | 9.2% |
| ChatGPT | 5.8% |
Here's the twist. The platforms citing the most sources per answer weren't the ones most likely to cite your page. Claude, for instance, routinely cited around 19 sources in a single answer, and still only landed on the target page 9.2% of the time.
Citation volume is not the same thing as citation of you. A chatty, source-heavy answer style doesn't mean your odds go up. It can mean the opposite, because you're now one voice competing in a much bigger crowd.
Finding 4: Bullet lists punch above their weight
Bullet lists made up under 7% of the content I tested but pulled in nearly 19% of citations. Roughly 3x over-represented.
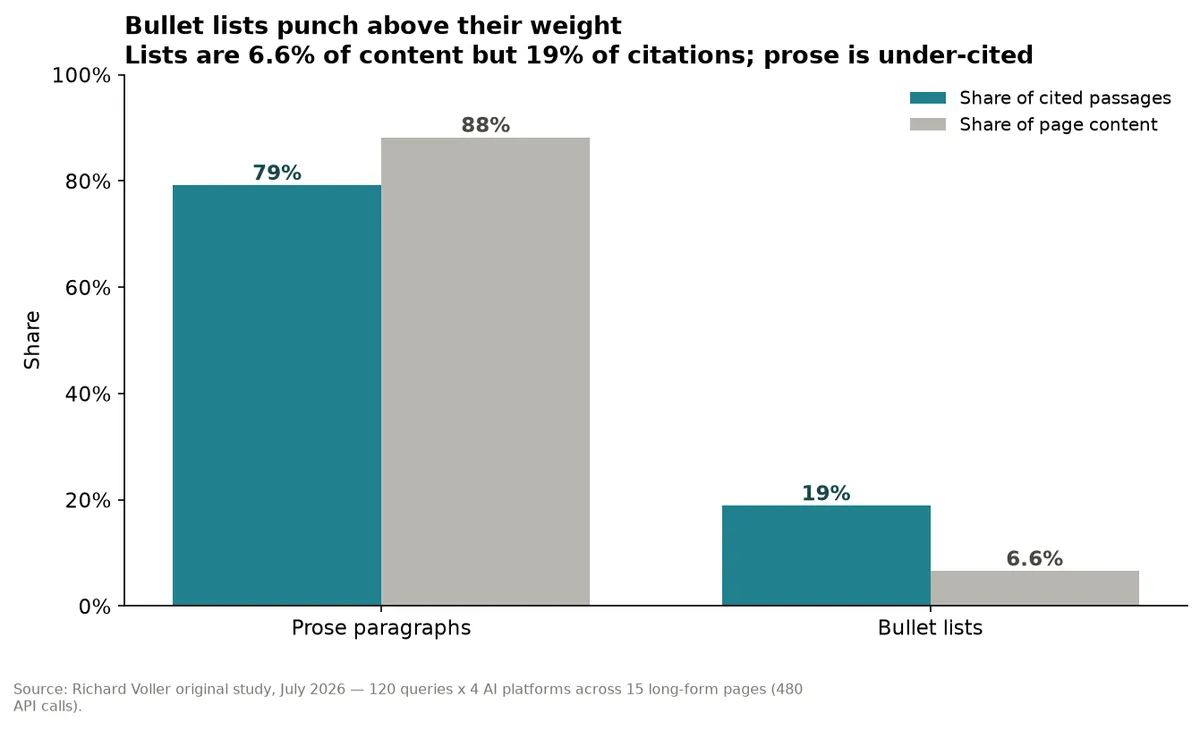
Prose still wins on raw citation volume, simply because there's more of it on any given page. But per unit of content, a list beats a paragraph every time in this dataset.
The practical move is the cheapest structural edit on this whole page: take your key takeaways and put them in a list, not a paragraph.
This tracks with what Ahrefs has published on the structural side of AI citation more broadly. Word count barely correlates with getting cited at all, but structure and clarity do (Ahrefs).
Finding 5: "Lost in the middle" is real, but it's a lean, not a cliff
When I deliberately buried the answer mid-page, the platforms still cited the correct middle passage 45% of the time. That beats any single other position on its own, but a majority of citations still drifted to the edges: 30% pulled up, 25% pulled down.
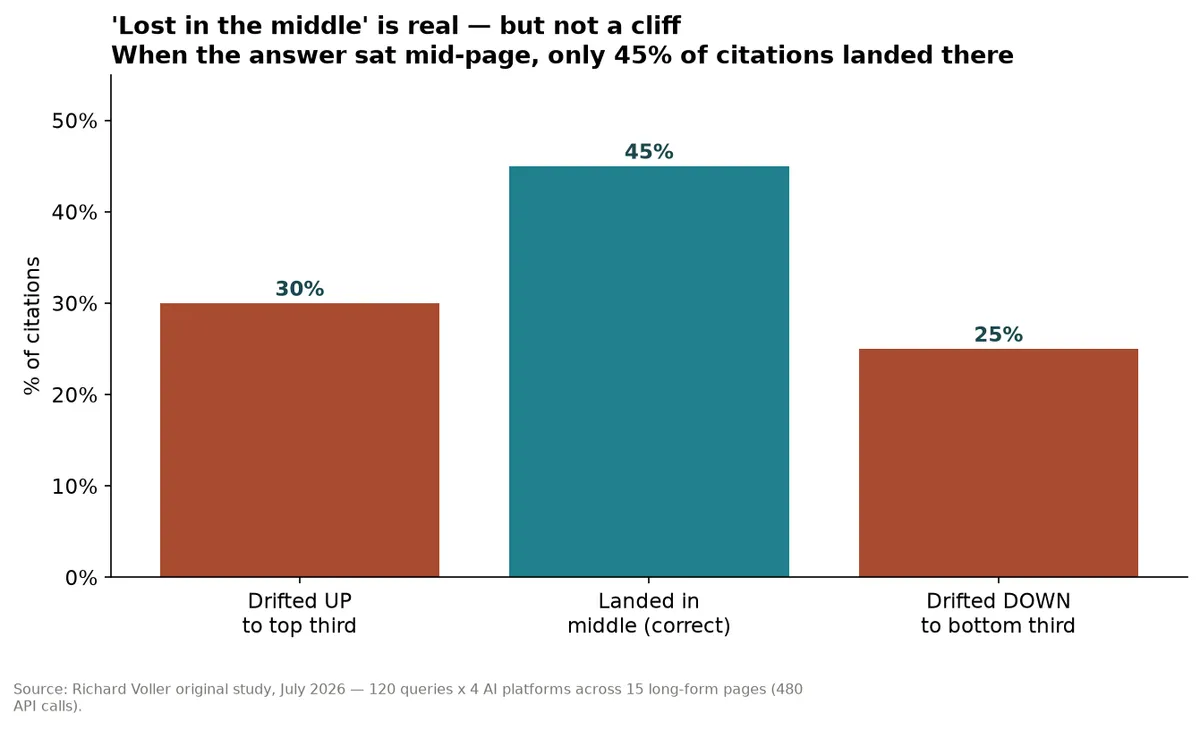
This is the practical, page-level version of the Stanford and MIT research cited under Finding 1. The middle isn't invisible. It's just disadvantaged.
Don't panic about content that happens to sit mid-page. Do stop relying on the middle for your single most important claim, because more often than not, that's not where the model actually looked first.
Finding 6: Third-party pages got cited 3x more than my own
My own posts were cited 4.4% of the time. Established third-party pages on the same topics were cited 14.4% of the time. That's a 3x gap.
I'm not burying this one. It's the least flattering finding in the entire study, and that's exactly why it's staying in. A study that only reports the numbers that make the author look good isn't a study, it's marketing with extra steps.
The likely driver isn't the writing itself, it's authority and entity recognition. A model has more reason to trust a source it's already seen cited elsewhere, repeatedly, by other sources it also trusts. Ahrefs has documented brand mentions and third-party authority as one of the strongest predictors of AI citation across their own research (Ahrefs), and my own numbers land right on top of that pattern.
The fix isn't purely on-page. It's earned mentions, coverage, and being talked about somewhere other than your own domain. I went deeper into how models treat brand-authored content specifically, and where that trust breaks down, in how content gets treated differently across Claude and GPT.
Finding 7: What actually won (a page teardown)
The single best-performing page in this study had a 56.2% cite rate. It wasn't the longest page in the set. It was dense, definitional, and tightly structured.
| Page type | Cite rate |
|---|---|
| Technical, definitional reference page | 56.2% |
| Encyclopaedic reference-style page | 31.2% |
| My best-performing page | ~6% |
| Two pages, including one of mine | 0% |
Structure beat length every time I checked it. The winning page read like a specification, not an essay. Short, self-contained sections, each one answering a single question before it moved on to the next.
Two pages scored zero, and one of them was mine. That's a structural teardown I'll be running separately, and I'd rather tell you that straight than quietly drop the page from the dataset and pretend it didn't happen.
How to structure content for AI citation (the playbook)
This section is deliberately the most scannable part of this whole piece. If a model reads it the way it read everything else in this study, this is the part most likely to get pulled.
- Front-load the answer. Your core claim and a direct definition belong in the first 30% of the page. Backed by Indig's 44.2% and CXL's 55%.
- Write answer capsules. A bold, 40 to 60 word direct answer straight after every H2.
- Turn takeaways into lists. Lists over-index roughly 3x in this dataset. Don't bury a takeaway in a paragraph if it can be a bullet.
- Don't bury your best claim mid-page. It only gets cited correctly 45% of the time from there.
- Make your H2s match real queries. Question-style headings win. AirOps found strong heading-to-query match lifts citation from around 29% to 41% (Search Engine Land).
- Build authority off-page. Third-party pages out-cited my own by 3x in this study. Earned mentions do work your own copy can't.
- Audit at scale, not by eye. You can proofread one page. You can't manually check structure across 300. If you're running this across a whole site, my Screaming Frog v24 MCP guide covers exactly how to crawl and check structure like this properly.
The honest limitations
Every piece I publish gets one of these. This one needs it as much as any of them have.
- 15 pages, 120 queries, 480 calls is directional, not census-scale. Treat the shape of the finding as reliable, and the exact percentages as a snapshot from one run.
- Passage-matching isn't perfect. Claude returns the cleanest exact cited text, which makes it the easiest platform to verify against. The others took more manual checking, and I'd rather admit that than pretend the process was uniform.
- This is a July 2026 snapshot. Citation behaviour moves fast. Re-run this in six months and I'd expect the shape to hold and the exact numbers to move.
- The bigger studies I've leaned on here, Indig, AirOps, Ahrefs, CXL, are all far larger than mine. I'm leaning on them for scale, and using my own data for the passage-level detail none of them have published.
Key takeaways
- Top third: 47% of citations, 37% of content. Front-load.
- Platforms differ. Gemini and Claude hug the top, Perplexity leans middle, ChatGPT is the most balanced.
- Lists over-index roughly 3x. Use them for anything you want cited.
- Mid-page answers get cited correctly only 45% of the time. Don't bury your best line there.
- Third-party pages out-cite your own by 3x. Build authority off-page, not just on it.
- Structure and authority beat raw length, every time I checked it.
That's the whole test, top to bottom. None of this replaces good writing. It just tells you where to put the good writing, so a model reading in a straight line, once, without ever going back, actually finds it.